Machine Trust: Authority, Rebuilt for Retrieval
Tactics for Visibility and Trust in AI-Driven Discovery

In the world of search, authority used to mean backlinks, domain age, and hitting all the right E-E-A-T signals. In the world of GenAI Search, authority means something else entirely: being retrievable, attributable, and machine-recognized as a trusted source. Here’s how to make that happen—practically, not theoretically.
This 12-point guide builds on the GenAI SEO shifts outlined in “Chunked, Retrieved, Synthasized,” but goes deeper on one essential question: how do you become a trusted source in the eyes of machines?
1. Embed Brand + Expert Identity in Structured Data
If an LLM can’t identify who published or authored content, your authority won’t travel. Structured data and Schema markup bridges that gap.
Use:
Organization schema (with sameAs, url, logo)
Person schema (with name, bio, credentials, and social handles)
Example: Your About page should use Person schema to link your CEO’s name to their LinkedIn and Twitter profiles. Add Organization schema to reinforce brand ownership.
Also, ensure this structured data is used consistently across all major pages—not just About or Contact. Redundancy in identity signals increases your odds of being correctly associated and retrieved by LLMs.
https://developers.google.com/search/docs/fundamentals/structured-data
2. Establish Machine-Recognizable Topical Consistency
Topical authority today isn’t about breadth—it’s about structured depth that retrieval systems can track.
Build semantic clusters with clean <h2> , <h3>, etc. structure
Maintain internal links between related assets
Stay narrowly focused within your area of expertise
Example: A company in HR tech should publish clearly siloed content hubs: onboarding, engagement, performance reviews—each internally linked and updated.
Avoid one-off blog posts that stray from your core topics. Instead, reinforce your expertise by expanding content clusters that reflect the taxonomy of how users—and machines—navigate your space.
3. Use Declarative, Factual Language in Key Sections
LLMs deprioritize vague content. Machines prefer confidence and clarity.
Weak: “We hope this solution improves onboarding.”
Strong: “This tool increased onboarding completion by 29% over six months.”
Pro Tip: Front-load facts—LLMs often weight the first few lines of a chunk most heavily. Use bold summary lines or callout boxes to signal key data.
Declarative statements aren’t just better for GenAI—they build reader trust too. Be specific with verbs, cite time frames, and attribute performance to clear actions for maximum impact.
4. Get Cited by Domains LLMs Trust
It’s not about backlinks—it’s about mentions from trusted sources that LLMs ingest and prioritize. And while mentions from high-trust domains are preferred, retrievability now includes reputable long-tail content and that trust now extends to more mid-tier domains —especially in vertical-specific queries.
Target:
TechCrunch, Wired, Crunchbase
Academic citations (Google Scholar, arXiv)
Government and NGO domains
Example: If you’re launching a product, pitch journalists whose stories appear in datasets known to train LLMs. A single attribution in a high-authority domain may carry more machine-weight than 50 unknown blogs linking to you.
Don’t chase every PR opportunity—prioritize those outlets with known machine trust signals and citations visible in tools like Perplexity’s Source View or Claude’s “tap to trace” interface. If your commentary appears on Perplexity Pages or Threads, that may carry more weight than a static blog mention, for example.
https://www.perplexity.ai/
https://www.anthropic.com/index/claude
5. Claim & Consolidate Knowledge Graph Entries
If you’re not in public knowledge graphs, GenAI systems may not understand or surface you.
To do:
Claim your Google Knowledge Panel
Submit an entity to Wikidata
Keep Crunchbase and LinkedIn entries up to date
Update Apple Business Connect if you’re a local business or orginization
Pro Tip: Use consistent entity names across all sources—“DuaneCo Inc.” should never also appear as “DuaneCo Software” or “DuaneCo Solutions” unless those are formal aliases declared in schema.
LLMs don’t just match strings—they ground content using entity IDs across graphs. The cleaner your presence, the more reliably you’ll be retrieved when it matters.
6. Feed Consistent Data to Public Sources
LLMs ingest more than just web pages—they pull structured data from trusted public repositories, too.
Post to:
Product Hunt for launches
PR Newswire for public announcements
Example: Launching a new feature? Cross-post the summary on Product Hunt and include the same messaging in your blog, press release, and social threads.
This triangulation reinforces the facts of your claim across high-credibility ingestion points—raising the odds your statement becomes part of the LLM’s structured memory.
7. Answer Questions on High-Trust UGC Platforms
Platforms like Reddit, Stack Overflow, and Quora aren’t just SEO curiosities—they’re core training data for GenAI systems.
You should:
Write answers that are structurally clear and factually grounded
Target threads in subs or communities tied to your vertical
Use formatting tools (bullets, bold, code blocks) to aid chunking
Example: A SaaS founder explaining how they reduced churn with user onboarding automation in r/SaaS will likely have more retrieval value than a keyword-optimized blog buried three clicks deep on their site.
These platforms are scraped for both tone and clarity—so aim to be human and helpful, but modular enough to be machine-quoted. An upvoted answer is a durable retrieval asset.
8. Repurpose Trusted Content Formats
LLMs prefer content that’s easy to parse, modular in structure, and already tied to familiar patterns like FAQs and How-Tos.
Use:
FAQPage, HowTo, QAPage schema
Short sections with <li>, <ol>, and <h3> tags
Clear formatting and standalone explanations
Example: Instead of a 1,500-word post on tax prep, break it into “How to file a 1099-K in California,” “How to amend a prior return,” etc.—each with its own schema and internal link.
Format shapes visibility. A tidy, structured piece with schema can be chunked and surfaced far more often than long-form narratives buried in generic blog layouts.
9. Publish Canonical Statements on Third-Party Platforms
Don’t rely solely on your site—publish your core claims in ecosystems GenAI systems are already reading.
Where:
Example: A GitHub repo README summarizing your model pipeline—with links to supporting blog posts—can act as a canonical content source for both developers and retrieval engines.
Think of third-party platforms as amplifiers: your words carry farther when published in trusted, machine-indexed spaces beyond your owned channels.
10. Use First-Person Anecdotes and Proof-of-Work
Generic claims don’t get surfaced. Specific, real-world examples are more likely to be chunked and retrieved by LLMs.
Include:
Numbers (“Processed 4.2M API requests in Q1”)
Time frames (“From Feb to April 2024…”)
Locations (“Tested in Ventura County”)
Example: Instead of saying “Our software is used widely in government,” say: “Deployed across 17 municipal departments in Ventura County between Jan–March 2024.”
GenAI systems are trained to favor data-rich chunks with grounding signals. The more concrete your example, the more retrievable—and trustworthy—it becomes.
11. Encourage Authorship Signals Across the Web
Named authorship still matters—to Google and GenAI systems alike.
Best practices:
Use consistent bylines, bios, and profile photos
Cross-link to a dedicated author profile or hub
Tag your content with Person schema and link to social handles
Example: Publish with your full name and title across Medium, company blog, and LinkedIn—and use Person schema with sameAs links to your social profiles to tie them all together.
https://developers.google.com/search/docs/fundamentals/creating-helpful-content
LLMs weigh authorship cues when ranking or generating responses. A consistent, credible author identity improves your retrievability and adds a layer of perceived trust.
12. Participate in or Publish Expert Roundups
LLMs love collective insight. Summarized consensus from recognized professionals often gets reused in machine answers. And while I personally dislike roundups, it turns out they may offer more utility than my jaded mind originally thought.
Expert roundups are likely ideal when combined with structured formatting and outbound links to contributor bios, enhancing both trust and retrievability. So the publisher needs to have their code and links in order for this to really benefit you.
How to lean into this opportunity:
Join roundups like “10 CMOs on the Future of Attribution”
Host your own—invite experts to weigh in and publish the thread
If you’re publishing, mind your code and get the details right
Make sure attributions include name, title, and organization
Example: If you’re quoted in a MarTech Today roundup with your company name and role, that segment becomes not just high-trust in human eyes—but also high-quality input for machine retrieval.
Machines favor clear structure and signals of credibility. Roundups offer both—and position you as a peer among thought leaders, not just a solo voice.
Pro Tip - it also appears structured LinkedIn comment threads are becoming increasingly crawled and cited—especially when tagged by authors with authority signals, so it’s worth exploring deeper engagement through this avenue.
Machine-Recognized Authority Signals - How Would You StackThem?
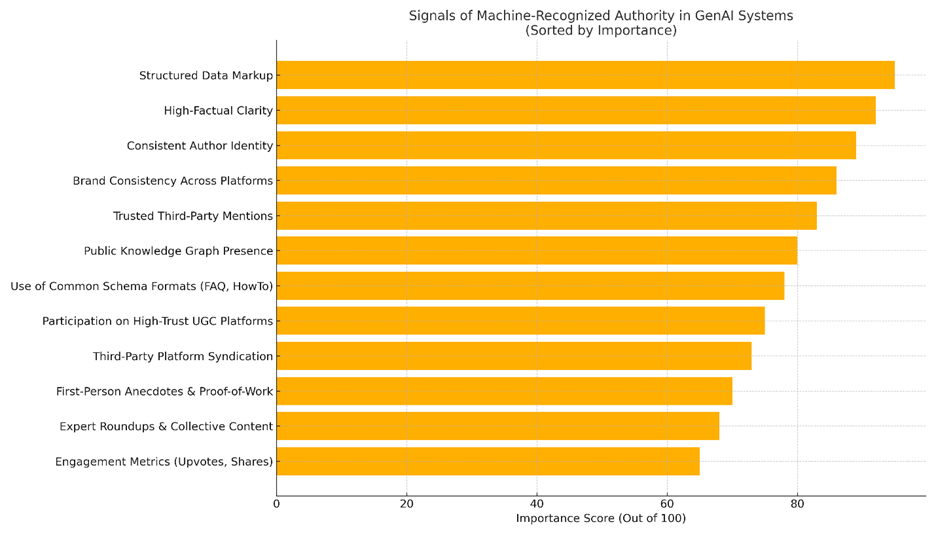
This chart ranks twelve signals based on how likely they are to influence retrievability and trustworthiness in GenAI systems like ChatGPT, Claude, and Perplexity. While scores reflect weighted importance, the cumulative effect of using multiple signals across platforms most likely increases retrievability odds. Once again, it’s about a combined effort of work, not shortcuts or a focus on “the one thing…” - that approach is dead. The Importance Score (out of 100) reflects my blended assessment of:
Inclusion in LLM training sets (via documentation, observed citations, and public indexing behavior)
Presence in Google’s current Search Central guidance and structured data documentation
Public research from GenAI SEO studies (e.g. BrightEdge, SE Ranking, BrightLocal)
Practical evidence of retrievability in AI summaries and citations
Top-scoring signals—like structured data, consistent author identity, and high-factual content—are foundational because they directly affect how machines understand, classify, and rank your content. Lower-scoring (but still relevant) signals such as expert roundups or proof-of-work enrich content, but are more situational and often depend on context or visibility through other trusted platforms.
These are not theoretical. They are real-world levers—validated by system behavior and current guidance—that marketers and creators can pull to become more findable and trusted in a machine-first discovery landscape.
As we wrap up, here’s a short final section with some final practical tips and resources:
Mini FAQ: Making Machine Authority Work for You
Q1: What if I can’t get mentioned by TechCrunch or Wired?
A: Mid-tier and niche publications still matter—especially in vertical-specific queries. What counts is repeated, structured, and attributed mentions across platforms LLMs ingest. Start with relevant trade outlets, Product Hunt, Reddit threads, or roundups in your space.
Q2: How do I know if my content is being retrieved by GenAI tools?
A: Use tools like Perplexity’s Source View or Claude’s “tap to trace” to reverse-engineer what sources they cite. Paste one of your URLs into ChatGPT’s browse tool and ask it where the content came from. Low or no attribution? Time to revisit your structure and signals.
Q3: Is this all just for big brands?
A: Not at all. GenAI engines don’t just favor size—they favor structure, consistency, and clarity. A well-tagged, factual blog post from a solo founder can beat a generic article from a Fortune 500 site—especially in long-tail or niche queries.
Q4: Do I need to change everything on my site right now?
A: No. Start with your highest-value or most visited content. Add schema, clean up headings, link to public profiles, and strengthen factual language. You can scale the rest over time—just make sure your best material reflects these new authority signals first.
Useful Links:
https://developers.google.com/search/docs/fundamentals/structured-data https://developers.google.com/search/docs/fundamentals/creating-helpful-content
https://www.brightedge.com/blog/helping-you-navigate-new-multi-search-universe-new-perplexity-research
https://seranking.com/blog/ai-overviews-sources-research/
https://www.brightlocal.com/research/uncovering-chatgpt-search-sources/
Final Thought
You don’t earn authority in a GenAI world the same way you did in a Google world. You don’t need thousands of backlinks. You need to be visible, consistent, and attributable—in machine-readable formats and trusted domains.
These 12 tactics aren’t speculative. They’re practical, built on real-world retrieval behavior. Start implementing them today to earn your place in tomorrow’s searchless, agent-driven digital landscape. You have to start bridging the gap between old and new, and the differences can be stark. Better to start building that bridge now.
Perfect thanks Duane! We're beginning to implement these with our clients but we're still trying to get the balance right of focusing on this and the need to hit leads/conversions. Any advice on this?
Really great article :) Thank you :)