Chunked, Retrieved, Synthesized - Not Crawled, Indexed, Ranked
The Practical Guide to GenAI Optimization

You’ll notice some familiar concepts from earlier guides — and that’s intentional. Retrieval-optimized content doesn’t require a new playbook every week. It requires *consistent execution* across systems and that we expand the new playbook logically. This guide takes foundational ideas from AI Doesn’t Read Like You and The 12 GenAI Search Metrics, and applies them tactically, at the chunk level — where LLMs start actually make decisions.
If traditional SEO optimized for clicks, GenAI systems optimize for chunks. To show up inside ChatGPT, Gemini, Perplexity, Claude, or other LLM-driven answer engines, this tactical guide is your blueprint. Here’s how you go beyond ranking to get retrieved, scored, reasoned over, and synthesized into useful answers. No fluff here, gang, just tactical, action-oriented suggestions:
1. Structure for Chunking & Semantic Retrieval
Clear structure helps LLMs pinpoint relevant content segments, known as "chunks."
Break your content into logical blocks (100–300 tokens each - more on this below).
Use semantic tags (<h2>, <h3>, <p>, <ul>, <ol>, <li>).
Each section should express a self-contained idea, clearly labeled with headings that echo natural queries.
Before vs. After Example:
Before (Flat Paragraph – No Chunking):
AI content is becoming more important today. Many people are using tools to generate it, and there are ways to optimize this content, but it’s complicated, especially if you're new to SEO. Most folks don’t think about retrieval pipelines, but that’s where the change is happening.
After (Chunked + Structured):
## Why Optimizing AI Content Matters
AI content is now central to how information surfaces in search. But optimizing it for retrieval is very different from traditional SEO.
## What’s Changing in GenAI Pipelines
Most GenAI systems don’t crawl and rank full pages. They break content into smaller units called “chunks” and score them based on semantic relevance.
## Why Structure Helps Retrieval
When your content is divided into clearly labeled sections, it becomes easier for LLMs to retrieve and reason over the right information.
Understanding Context Windows in Plain Language
LLMs use tokens, not words — but here’s the translation:
1 token ≈ 0.75 words (please remember, the ≈ means approximate/roughly)
Source: https://platform.openai.com/tokenizer
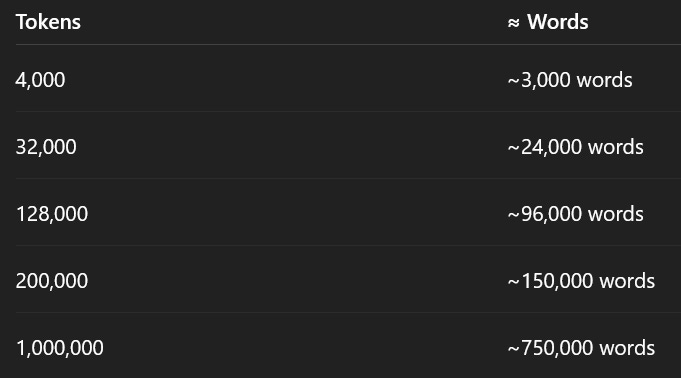
Even with a million-token window, GenAI still retrieves content in chunks. Structure still wins.
Current Context Limits by Platform (as of June 2025)
GPT-4 Turbo: 128K tokens (~96K words)
sourceGoogle Gemini 1.5 Pro: Up to 2 million tokens (~1.5 million words)
sourcePerplexity AI: 4K–32K tokens (~3K–24K words)
sourceClaude 3 Opus: 200K–1M tokens (~150K–750K words)
source
2. Prioritize Clarity Over Cleverness
GenAI systems prefer clear, direct language that matches user queries closely.
Use plain language questions and direct answers.
Avoid jargon, metaphors, and clever intros. Using an acronym? Expand it.
Example: “Do polarized sunglasses block blue light?” vs. “The magic of modern eyewear.”
Pro Tip: Run your headers and FAQs through tools like AlsoAsked to match real-world phrasing.
3. Make Your Site AI-Crawlable
AI crawlers (GPTBot, Google-Extended, CCBot) need clear, open access.
Don’t block key bots via robots.txt.
Avoid content hidden in JavaScript or PDFs.
Use schema.org markup extensively.
Resource: OpenAI GPTBot Docs
CMS Tip: WordPress users can use Yoast or Rank Math. Notion users: structure pages with Heading 2/3 blocks and dividers — these are chunk-friendly.
4. Establish Trust & Authority Signals
LLMs favor sources that look trustworthy.
Display author bylines, credentials, and dates.
Link to high-authority sources.
Example: “Dr. Eliza M., PhD in Cognitive Neuroscience, updated May 2025.”
5. Build Internal Relationships Like a Knowledge Graph
Help retrieval systems connect the dots.
Use consistent anchor text across related pages.
Build content clusters and link between them.
Example: Link “RAG architecture” to “vector database basics.”
Where we were, and still are, which works for current, traditional search systems…
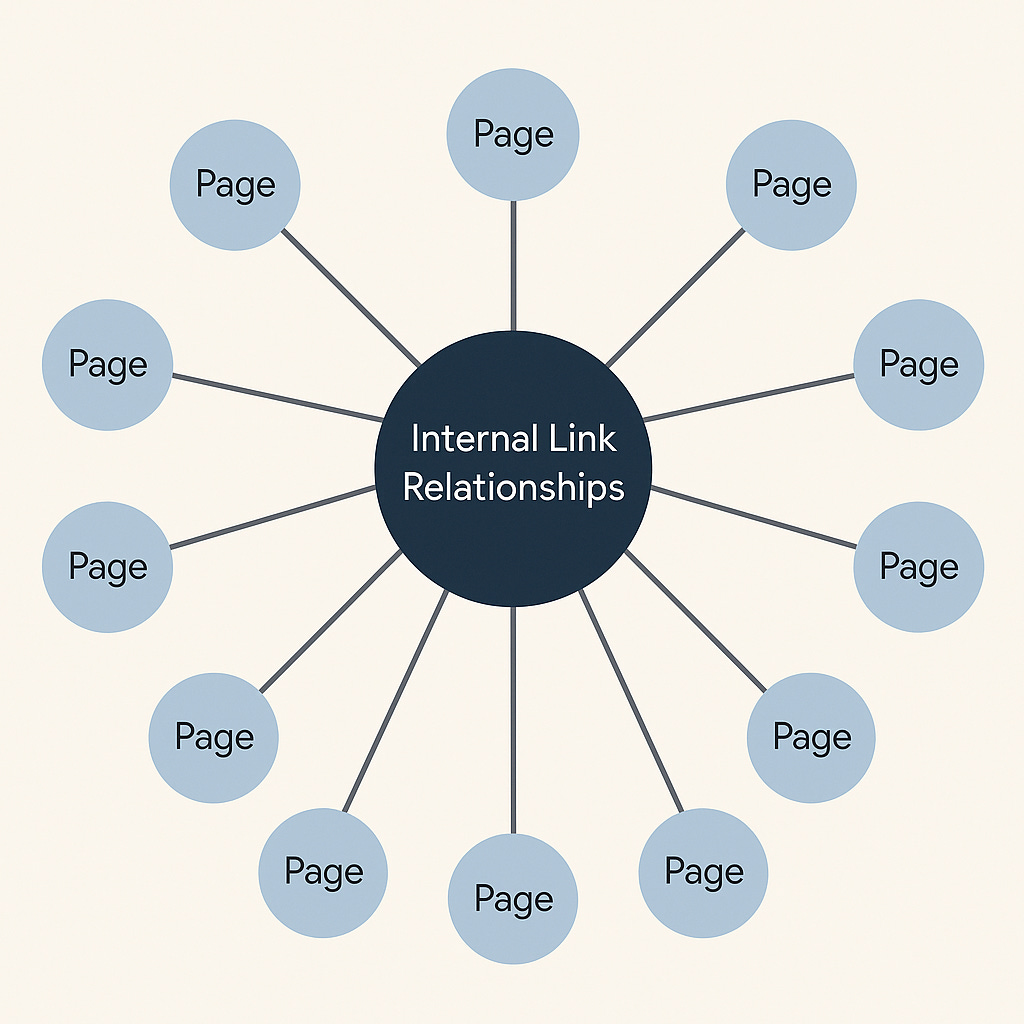
This structure may look familiar — and that’s no accident. Over the past 20 years, SEOs have evolved internal linking from thematic silos (Bruce Clay, ~2004), to hub-and-spoke models (~2010), to topic clusters (HubSpot, Backlinko, ~2016), and more recently, entity-based interlinking (Aleyda Solis, Kevin Indig, ~2022). This image over-simplifies a bit, but you know these models well by this point.
Now here’s what’s changed:
In GenAI systems, internal links do more than pass link equity or reinforce relevance — they shape the retrieval map LLMs use to pull and score content chunks. Strong internal linking doesn’t just help with SEO anymore — it helps your content get retrieved, reasoned over, and included in AI-generated answers.
This isn’t just about architecture. It’s about accessibility — for machines.
This is where we need to go for modern search systems, the hybrid systems we see in use today…
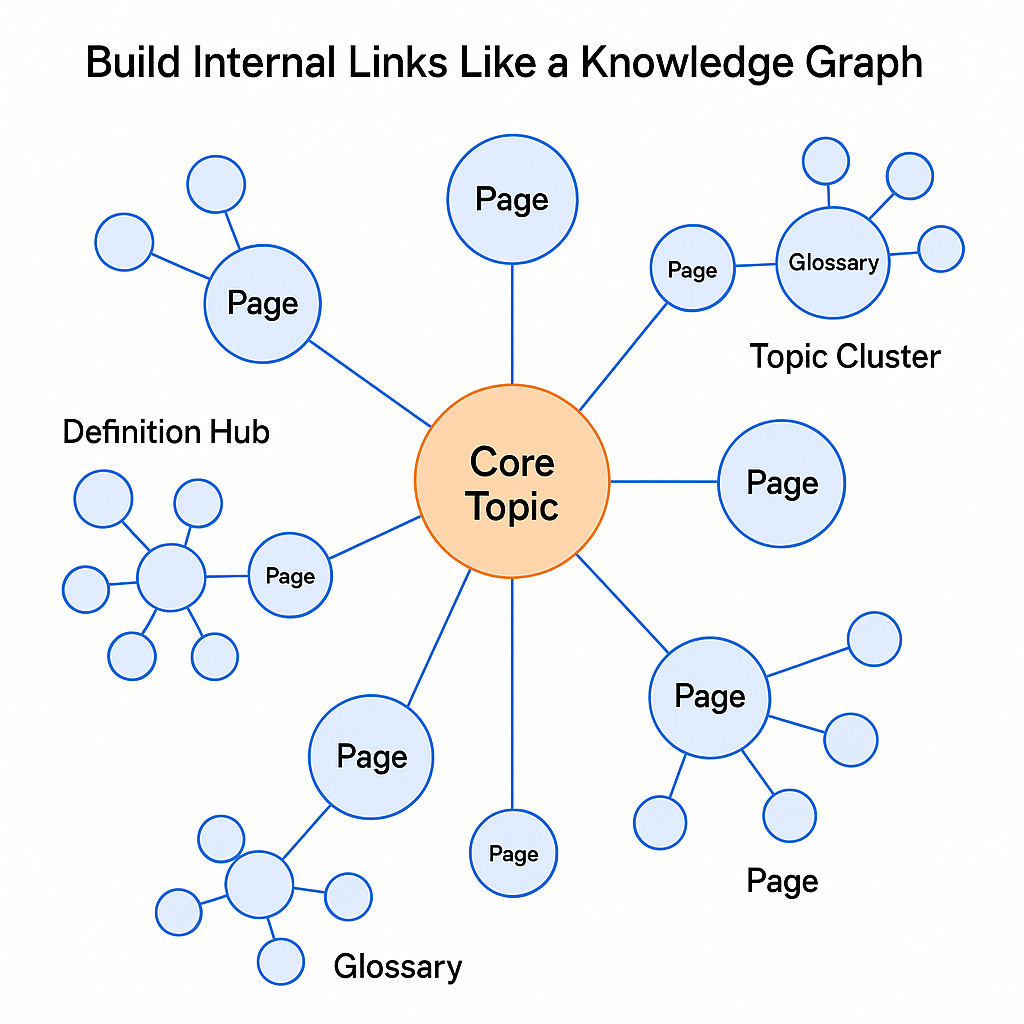
This isn’t just a map of pages — it’s a map of meanings.
Traditional internal linking focused on navigation and hierarchy. But in GenAI systems, what matters is how your content expresses relationships between concepts.
Think of each page or section not just as a destination, but as an entity connected to others through meaning:
“Explains,” “compares,” “supports,” “defines,” “is used in,” “is built on.”
This is the mindset shift:
You’re no longer just linking URLs. You’re building a retrieval-ready knowledge graph out of your own website — one that mirrors how LLMs actually understand and surface information.
6. Cover Topics Deeply and Modularly
Comprehensive content = more retrieval hooks.
Cover the what, why, how, and vs. alternatives.
Use modular blocks: TL;DRs, side-by-sides, use cases.

Modular Content Ideas:
Pros vs. Cons tables
Glossaries
How-to guides
FAQs (Frequently Asked Questions)
Use-case pages
Comparisons (e.g. “RAG vs Fine-Tuning”)
7. Optimize for Retrieval Confidence
Confident, declarative phrasing is more likely to be retrieved and featured in GenAI answers.
Use clear, assertive language when presenting factual claims.
Avoid vague qualifiers like “some believe” or “it could be argued” — they reduce retrieval strength.
Pitfall: Vague claims like “experts believe” often get filtered out.
Example:
Yes - “GPT-4 supports 32k context windows.”
No - “GPT-4 might handle larger input sizes…”
But what if you're operating in a legal, healthcare, or enterprise setting where everything has to go through legal or PR review? Declarative language can make teams nervous — even when it’s accurate. Still, if you hedge every sentence, your content won’t get retrieved at all.
Working With Legal and PR: Finding the Retrieval Balance
If you're in a regulated industry, you don’t need to give up on retrieval optimization — but you do need to collaborate. Success will require coming to logical agreements and building an internal guidance framework that allows you (the marketer) the content required to be successful, while still adhering to guidance to protect the business.
1. Educate internal teams - Help legal, compliance, and PR stakeholders understand how GenAI retrieval works. Explain that confidently phrased, fact-based content improves visibility — and that clear does not mean reckless. Framing it as "being included in answers vs. being invisible" can shift the conversation.
2. Use two-tiered phrasing - Present the assertive, user-facing statement first, followed by any required disclaimers. For example:“Vitamin D supports immune function. Consult your doctor for personalized advice.”
3. Build an approved language library - Work together to create reusable, retrieval-friendly phrasing that passes legal review. This makes future content faster to produce and more consistent across teams.
4. Use schema markup for clarity - Tag pages with LegalWebPage, MedicalWebPage, or relevant types from schema.org to give AI systems context about why cautious phrasing is used. This helps prevent misinterpretation.
8. Add Redundancy Through Rephrasings
Semantic redundancy increases your retrievability footprint — think of it as casting a wider net in vector space.
Rephrase key ideas 2–3 times using plain synonyms.
Spread them across different chunks: intro, body, summary.
Use phrasing that mirrors natural query variations.
Examples:
“Optimize for retrieval”
“Make your content easier for AI systems to find”
“Improve inclusion in LLM responses”
Why it works: Embeddings don’t rely on keywords — they match meaning. Repeating ideas with variation makes your content semantically visible across more prompts.
9. Create Embedding-Friendly Paragraphs
LLMs embed and score chunks based on coherence and clarity.
Stick to one idea per paragraph.
Use short, declarative sentences.
No - Mixed Topic Block:
Vector databases are important for GenAI retrieval. They work alongside BM25, which ranks documents by keyword frequency. These models also use embeddings to match meaning.
Yes - Embedding-Friendly Rewrite:
Embeddings allow GenAI systems to match queries with meaningfully similar content — even when the exact words don’t match.
Why it matters: The cleaner the paragraph, the more precise the vector — which leads to better retrieval and scoring.
10. Include Latent Entity Context
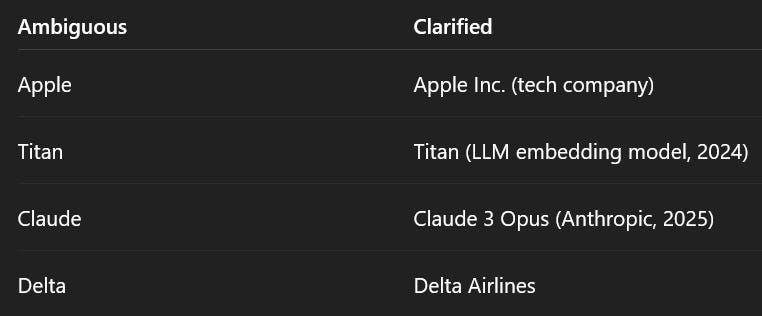
If your content includes ambiguous names, add context.
Clarify brands, people, tools, and terms with specificity.
Add dates, model names, or domains of use.
Ambiguous vs. Clarified Entities
Pro Tip: Even image captions and diagrams can help disambiguate — don’t leave LLMs guessing.
11. Use Contextual Anchors Near Key Points
LLMs evaluate the internal coherence of a chunk. If the claim and its context are separated, you risk retrieval failure.
No - Spread Too Far:
“Polarized lenses reduce glare.”
...later on...
“This helps fishermen and drivers.”
Yes - Coherent Anchor:
“Polarized lenses reduce glare from water and glass — a key benefit for drivers and anglers who rely on visibility in high-glare environments.”
Why it works: Each chunk is scored as a unit. LLMs don’t always pull context from other sections — you need to make your reasoning self-contained.
12. Publish Structured Extracts for GenAI Crawlers
Some GenAI systems prioritize snippets and summaries.
Use bolded bullets, Key Takeaways, or Quick Recap blocks.
Keep them concise and informative.
Example:
Chunk content with semantic headers
Use schema markup
Write for clarity and retrieval, not just style
13. Feed the Vector Space with Peripheral Content
Supporting content increases topic density — which increases your retrieval chances.
Cluster Example for “LLM Retrieval Pipelines”:
“What Is Retrieval-Augmented Generation?”
“Dense vs Sparse Retrieval”
“Top Vector DBs for 2025”
“BM25 vs Hybrid Scoring”
“Glossary: GenAI Search Terms”
Try This: Search “Top vector databases 2025” on Perplexity.ai or Brave Search. Does your content surface in a summarized or synthesized response? If not, your chunk structure and retrieval signals likely need refinement.
Getting Started This Week
Choose a high-traffic article and break it into <h2>-defined chunks.
Add a “Key Takeaways” block summarizing the main points.
Add semantic links to related content and glossaries.
In 7 days, check Perplexity or Brave to see if your content now appears in AI-generated answers.
Final Thoughts
Traditional SEO aimed for clicks. GenAI demands retrieval and reasoning. Don’t optimize for pageviews — optimize for comprehension, context, and inclusion in machine-generated answers. In truth, we’re living in a place between two worlds right now. Traditional search and the systems that power it, and hybrid search built on generative-ai systems. And as professionals, you need to build for both worlds, currently. The good news is you can learn this new direction, the “new rules” if you will, and start experimenting immediately. As consumers move from how they used to get answers to how they will get answers, you’ll know what works for you and what to do as we all transition. Just don’t make the mistake of thinking there is a status quo right now. There is not. There is only growth for survival now.
Further Reading:
Another great read, fair play. Point 7 around legal teams is so good, particularly timely for us as we're about to start this with a heavy legal compliance brand soon
Can I ask you a question? I am working on a project for a client and I do NOT have WP block text functionality, only an RTE. Would you recommend that I create a new, smaller RTE “chunks” instead of adding the copy in on a super large chunk?